Comment déterminer la capacité à prédire un résultat d’un modèle de classification? On utilise souvent la matrice de confusion pour comparer les résultats d’un algorithme à la réalité. Dans cet article nous allons voire comment la lire et la fabriquer. Pour cela, nous allons faire tourner sur un échantillon de 300 mails un modèle d’analyse de sentiments. Chacun des mails aura été au préalable analysé manuellement. Chaque mail peut être catégorisé comme négatif, neutre ou positif.
Pour analyser les résultats et en déduire la précision, nous allons dessiner une matrice de confusion. Pour rappel, une matrice de confusion permet d’évaluer les performances d’un modèle de classification d’apprentissage en IA.
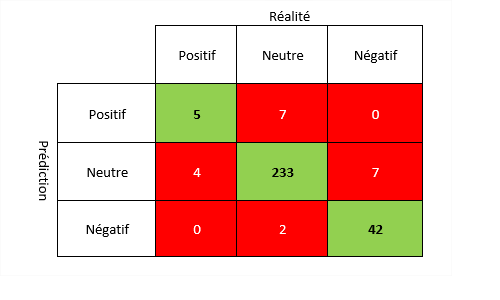
Voici comment lire la matrice de confusion :
- En vert les résultats identiques entre la réalité et la prédiction (soit 5 + 233 + 42 = 280).
- En rouge les résultats divergents entre la réalité et prédiction. Voici un exemple de lecture :
- Il y a 4 résultats positifs dans la réalité qui ont été classés dans la catégorie neutre par le modèle (colonne 1 ligne 2).
- Il y a 0 résultat positif dans la réalité qui ont été classés dans la catégorie négatif par le modèle (colonne 1 ligne 3).
Calcul de la performance du modèle
La précision globale du modèle est la proportion de prévision correcte c’est-à-dire la somme du nombre de résultats identiques sur le nombre total de résultats.
![\[PrecisionGlobale=\frac{233+5+42}{300}=0.93=93 \%\]](https://wordpress.fangorne.ddnsfree.com/wp-content/ql-cache/quicklatex.com-cffce17d8d5868a78e2082fd5133e3e6_l3.png "Rendered by QuickLaTeX.com")
Il faut faire attention à la précision globale. Le choix de la métrique doit se faire en fonction de l’étude, c’est-à-dire de la problématique que l’on veut résoudre, en particulier lorsqu’il y a un problème de déséquilibre de classe. L’indicateur F-Score est souvent utilisé pour déterminer la performance d’un modèle d’apprentissage automatique. Dans notre cas, nous pouvons de plus simplifier ces calculs car nous sommes surtout intéressés par la détection de commentaires négatifs. En procédant ainsi, il ne reste plus que deux catégories (négatifs et autres).
La précision ici permet d’observer sur tous les commentaires négatifs prédits combien étaient vraiment négatifs.
![\[Precision=\frac{42}{42 + 7 + 0}=0.86=86 \%\]](https://wordpress.fangorne.ddnsfree.com/wp-content/ql-cache/quicklatex.com-b77635b69b6fe66eca6dbe87bc1964c0_l3.png "Rendered by QuickLaTeX.com")

Le rappel montre la capacité du modèle à identifier tous les commentaires négatifs
![\[Rappel=\frac{42}{0 + 2 + 42}=0.95=95 \%\]](https://wordpress.fangorne.ddnsfree.com/wp-content/ql-cache/quicklatex.com-998500a3764d9f33344b63207baef2ae_l3.png "Rendered by QuickLaTeX.com")
Enfin le F-Score, l’indicateur final dont on se servira pour déterminer la performance du modèle est la moyenne harmonique de la précision et du rappel.
![\[FScore=2*\frac{Precision*Rappel}{Precision +Rappel}=0.9=90 \%\]](https://wordpress.fangorne.ddnsfree.com/wp-content/ql-cache/quicklatex.com-245b2355d57cea74b68be5e20528d5cf_l3.png "Rendered by QuickLaTeX.com")
La performance du modèle pour repérer les commentaires négatifs est donc de 0.9.